[逻辑架构图]
本章知识点从宏观范式向底层微观的高维数据特征提取逐级深挖,呈现出由“离散关系寻找”到“连续空间降维”的严密逻辑链条:
-
认知基石:界定监督学习与非监督学习的边界(范式与数据结构特性)。
-
离散规则与图谱拓扑:从离散项集的频繁模式挖掘(关联规则 Apriori / FP-Growth),自然延伸到基于图结构的全局关联度量(PageRank算法)。
-
空间距离与聚集态(静态划分):基于距离度量与概率密度的聚类分析(K-means、层次聚类、DBSCAN)。
-
空间映射与拓扑保持(动态过渡):自组织映射图(SOM)作为降维与聚类的桥梁,实现高维到低维的非线性保流形映射。
-
线性特征提取与成分拆解(全局降维):主成分分析(PCA)、非负矩阵分解(NMF)、独立成分分析(ICA)与探索投影寻踪(EPP),在不同约束(方差、非负、独立性)下寻找基向量。
-
非线性流形与几何重构(局部降维):从主曲线/主曲面到多维缩放(MDS)及其非线性变体(Local MDS),在高维卷曲空间中还原数据的内蕴几何。
[深度整理正文]
0. 机器学习基石:监督与非监督学习
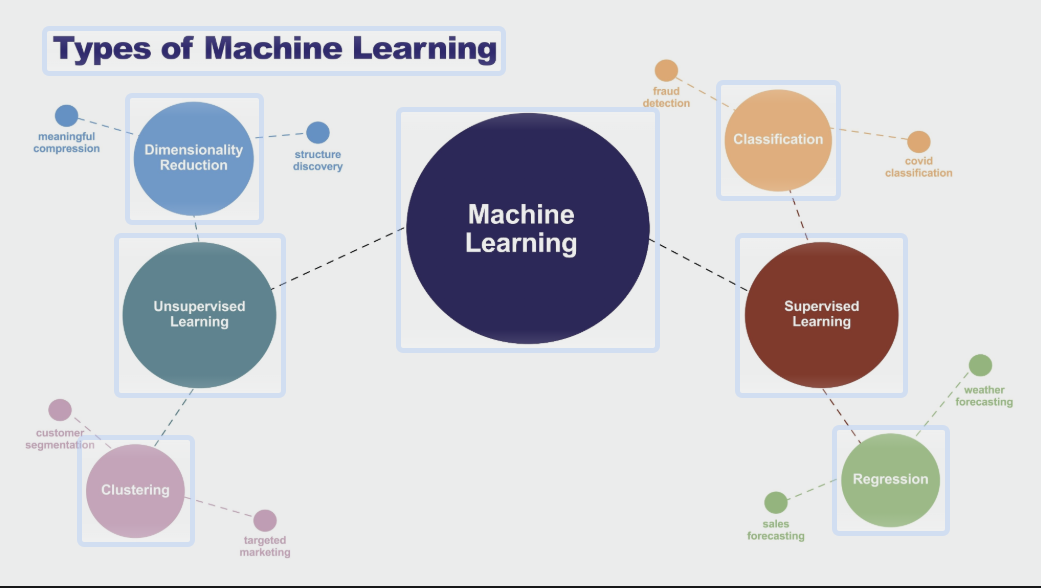
机器学习领域中,监督学习和非监督学习是两种最基础且核心的范式。本质区别在于训练数据中是否包含“答案”(Labels)。
-
监督学习(Supervised Learning):
核心目标是建立一个从输入特征空间到输出标签空间的映射函数 。常见任务包括回归(预测连续数值)和分类(预测离散类别)。典型算法如逻辑回归、SVM、决策树、神经网络等。
{系统底层视角:监督学习的训练过程(尤其是深度神经网络的前向与反向传播)本质上是密集型矩阵乘法(GEMM)。在底层依赖于高度优化的 BLAS 库,极度消耗 GPU 的 Tensor Core 算力和 HBM(高带宽内存)。其数据读取模式通常是高度顺序化的批处理(Batching),对 CPU 的预取器(Prefetcher)极其友好。}
-
非监督学习(Unsupervised Learning):
数据仅包含特征向量 ,模型需自行发现数据内部隐藏的结构、分布或相似性。常见任务包括聚类(Clustering)、降维(Dimensionality Reduction)和关联规则(Association Rule)。
{系统底层视角:非监督学习(如复杂的聚类和流形学习)往往涉及大量的不规则访存(Irregular Memory Access)和全局距离矩阵计算。例如构建 的距离矩阵会导致极高的内存占用( 复杂度),极易引发 CPU 的 L3 Cache 穿透(Cache Thrashing)和 TLB Miss 暴增。}
-
两者的联系:相辅相成,常通过非监督预处理(如 PCA 降维或异常检测)来降低监督学习的维度灾难;终极目标一致;在半监督学习和自监督学习(如 GAN、掩码自编码器)中技术交织。
1. 离散关系挖掘:关联规则与 PageRank
本部分探讨如何从海量、无序的离散数据或图网络中寻找隐藏的强关联性。
1.1 关联规则(Association Rules)
核心目标是发现“买了 A 大概率买 B”()的规则。核心指标为:
-
支持度(Support):,衡量规则的普适性。
-
置信度(Confidence):,衡量规则的可靠性。
-
提升度(Lift):,衡量 对 的正向促进作用( 为强关联)。
Apriori 算法:利用先验性质(频繁项集的子集必频繁,非频繁项集的超集必非频繁)进行搜索空间剪枝。
- 瓶颈:{每次生成候选集都需要对底层数据库进行全表扫描(Full Table Scan)。在操作系统层面,如果数据集超出物理内存容量,会引发严重的 Page Fault 和磁盘 I/O 拥塞,导致性能呈指数级衰减。}
FP-Growth 算法 :
为了解决 I/O 瓶颈,仅需扫描两次数据库。它将数据压缩成一棵 FP 树(Frequent Pattern Tree),通过递归地在树上搜索挖掘,免去了候选集的生成。
- {系统底层视角:虽然 FP-Growth 解决了磁盘 I/O 问题,但 FP 树是一种典型的基于指针的非连续数据结构(Pointer-chasing)。在 CPU 执行时,这会导致极低的空间局部性(Spatial Locality),使得 CPU Cache Line 的命中率骤降。现代系统通常会引入内存池(Memory Pool)技术将树节点分配在连续内存块上,以缓解 Cache Miss。}
1.2 附加扩充:PageRank 算法(网络结构的关联规则)
{如果说关联规则是在发掘“物品”间的共现关系,PageRank 则是发掘“节点”在复杂网络中的核心地位。
-
核心逻辑:基于马尔可夫链(Markov Chain)。一个网页的重要性取决于链接向它的页面的重要性。
-
数学表达:,其中 是网页权重向量, 是状态转移矩阵(列归一化的邻接矩阵), 是阻尼系数(Damping Factor,解决孤岛问题)。
-
系统底层视角:PageRank 的求解本质上是超大规模稀疏矩阵-向量乘法(SpMV)。由于网页图的连接高度随机,导致在计算时对 向量的访存是极其离散的。工程实现上必须采用 CSR(Compressed Sparse Row)或 CSC 压缩格式来存储图,并依赖于分布式计算框架(如 MapReduce 或 Pregel 图计算引擎)跨多台服务器切分图结构,解决单机内存带宽(Memory Bandwidth)打满的问题。}
2. 空间聚集态寻找:聚类分析(Clustering)
聚类的本质是寻找数据在特征空间中的聚集密度。核心在于衡量“相似性”与距离(如欧氏距离 )。
2.1 组合算法与混合模型
-
基于原型的聚类(K-means & K-medoids):组合算法。K-means 将点分配给最近的质心并迭代更新均值;K-medoids 强制中心点必须是原始样本点,牺牲速度换取对异常值的鲁棒性。
- {系统底层视角:在计算千万级点到 K 个中心的距离时,欧氏距离公式中的开方操作非常耗时。由于仅需比较距离相对大小,底层代码通常会去掉平方根,直接使用平方和。现代编译器(GCC/Clang)会通过循环展开(Loop Unrolling)和 SIMD 指令(如 AVX-512 的 FMA,融合乘加)将距离计算并行化。}
-
基于模型的聚类(GMM):混合模型。假设数据由多个概率分布混合生成,采用软聚类(隶属度),通过 EM(期望最大化)算法求解。
2.2 层次聚类(合并与分裂)
构建树状结构(Dendrogram),无需预设 。
-
组合方式:最短距离法(易生链状效应)、最长距离法、平均距离法、离差平方和法(Ward’s Method)。
-
{性能代价:合并层次聚类的时间复杂度通常为 。在海量数据下,这不仅是算力的梦魇,更是内存的黑洞。维护动态的接近矩阵(Proximity Matrix)会产生巨量的随机内存写操作。}
2.3 模式寻找与密度聚类
- DBSCAN & Mean Shift:基于数据密度的波峰定位。无需预设 K,能发现异形簇并自动剔除噪声。
3. 拓扑保持的桥梁:自组织映射图(SOM)
SOM(Kohonen 网络)连接了聚类与非线性降维,实现高维数据到二维网格的保拓扑映射。
-
三大机制:竞争(找 BMU)、协作(影响邻居)、学习(权重自适应)。
-
退火效应:学习率 和邻域半径 随时间衰减,完成从全局粗调到局部微调的过渡。
-
本质属性:区别于 K-means 的“硬划分”,SOM 展示了数据的过渡与演变关系(流形结构的展开)。它生成的 U-Matrix 能够直观显化聚类边界。
-
{系统底层视角:SOM 的算法具有极强的数据依赖性(Data Dependency)。由于每次样本输入都会更新 BMU 及其邻域的权重,传统的多线程并行化会遭遇严重的竞态条件(Race Condition)。在工程实现中,通常需要采用 Map-Reduce 思想或者延迟更新策略(Batch-SOM),累积一个批次的梯度后再统一修改权重。}
4. 全局特征提取与降维:线性拆解的艺术
面对高维诅咒,如何提取最“干净”的信号?
4.1 主成分分析(PCA)与 主成分
寻找数据方差最大的方向,通过线性投影将原始变量转换为正交的主成分。
- {系统底层逻辑:PCA 的数学本质是协方差矩阵的特征值分解,或对原始数据矩阵直接进行奇异值分解(SVD)。在 CPU 执行 SVD 时,高度依赖 LAPACK 库中的 Cache-Blocking(缓存分块)优化技术。通过将巨型矩阵切分成小块(Block)装载入 L1/L2 Cache 中,最大化数据的重用率。}
4.2 非负矩阵分解(NMF)
寻找 ,施加严苛的非负约束(),强制实现“部分构成整体”(Parts-based representation)。
-
物理意义:无抵消效应,高度可解释。 提取基石(特征/局部), 提供软聚类权重。
-
{底层数值稳定性:NMF 的乘性更新规则在分母处含有矩阵乘法。由于浮点数精度限制(IEEE 754),随着迭代深入,分母可能无限趋近于 0 导致溢出或
NaN。严谨的系统级实现必须在分母加入微小的扰动项 (如1e-9),并严格防御浮点数异常(Floating-Point Exceptions)。}
4.3 独立成分分析(ICA)与 探索投影寻踪(EPP)
-
ICA:比正交更强,追求“统计独立”。通过最大化非高斯性解决盲源分离问题(如鸡尾酒会效应)。
-
EPP:基于投影指数寻找数据的“神仙视角”(非正态分布视角),揭示隐藏的聚类结构。
5. 局部几何重构:流形学习与非线性降维
当数据位于高维卷曲空间(如瑞士卷)时,线性降维失效。
5.1 主曲线与主曲面
- PCA 拟合直线的局限在主曲线被打破,它通过自相容性寻找穿过数据中心的非线性骨架;主曲面则延展成高维空间中的低维薄膜。SOM 在收敛后即为离散的主曲面。
5.2 多维缩放(MDS)及其局部变体(Local MDS)
-
MDS:仅通过给定的距离矩阵(或相似度矩阵)重建空间点的坐标,追求重构后距离与原始距离误差最小。
-
Local MDS / 非线性降维(如 Isomap、LLE):只关注并保持局部邻居的相对位置(测地线距离)。只要局部微元是对齐的,整体的卷曲拓扑就能被“拉平”而不断裂。
-
{系统扩展:这类算法必须构建 -最近邻(KNN)图。暴力构建的复杂度是 。在底层工程中,绝对不会直接算全局距离表,而是必须借助空间索引结构(如 KD-Tree、Ball-Tree)或 HNSW(分层导航小世界图)算法,将时间复杂度降至 级别,否则在实际业务(如千万级词向量聚类)中内存直接 OOM(Out Of Memory)。}
[边界知识联动]
本章涵盖的机器学习算法模型,在实际落地时与操作系统底层的四大组件存在极深的制约与联动关系:
-
CPU Cache 与 内存布局(Memory Layout)
- 联动:算法的访存模式直接决定了其运行速度上限。FP-Growth 的树形跳转、PageRank 的图漫游、合并聚类的矩阵更新都属于随机访存,严重破坏 Cache 的空间局部性。现代系统级 ML 库(如 FAISS、XGBoost)均大量使用列式存储架构(Columnar Storage)和数据对齐(Memory Alignment)来强行喂饱 CPU Cache。
-
指令集与向量化(SIMD)
- 联动:K-means 和 PCA 等包含密集的距离计算和点乘操作。这类操作极其适合由现代 CPU 的 AVX-2 / AVX-512 指令集打包处理。缺乏向量化优化的 C++ 代码执行 KMeans,相比于底层开启 SIMD 优化的版本,吞吐量可能相差几十倍。
-
虚拟内存与 Page Fault 机制
- 联动:对于 Apriori 和大规模距离矩阵计算(MDS、层次聚类),若数据结构超过物理内存,OS 会将数据换页至 Swap 分区(硬盘)。高频度计算会引发灾难性的 Page Cache 颠簸(Thrashing)。此时算法必须修改为 Out-of-Core 模式或采用块级处理。
-
浮点运算标准与硬件陷阱
- 联动:在 NMF、GMM 等需要长期迭代逼近极值的算法中,梯度消失、概率连乘下溢是常态。底层经常需要将概率域转换到对数域(Log-Sum-Exp 技巧)计算,规避底层 FPU(浮点运算单元)处理极小数字时退化为次正规数(Subnormal Numbers)导致的数百倍时钟周期延迟。